
-

-

-

- Austria (27)
- General (16)
- HowTo (122)
- IT Security (129)
- Linux (127)
- Networking (65)
- Other (3)
-

- CDemu - a free, gpl cd/dvd-rom device emulator for linux
- heatpumpMonitor - Monitoring a Stiebel Eltron LWZ
- ignis backup tool - the heat-strengthened backup tool
-

- December 2021 (2)
- September 2019 (1)
- May 2019 (1)
- April 2019 (1)
- January 2019 (1)
- October 2018 (1)
- August 2018 (1)
- February 2018 (1)
- September 2017 (1)
- August 2017 (2)
- May 2017 (1)
- April 2017 (1)
- February 2017 (1)
- January 2017 (2)
- December 2016 (1)
- November 2016 (2)
- October 2016 (1)
- September 2016 (1)
- August 2016 (1)
- July 2016 (2)
- April 2016 (1)
- March 2016 (3)
- February 2016 (4)
- January 2016 (2)
- December 2015 (2)
- November 2015 (2)
- September 2015 (2)
- July 2015 (5)
- June 2015 (4)
- May 2015 (2)
- February 2015 (1)
- January 2015 (4)
- December 2014 (1)
- November 2014 (5)
- October 2014 (4)
- September 2014 (1)
- August 2014 (4)
- July 2014 (3)
- June 2014 (5)
- May 2014 (5)
- April 2014 (1)
- March 2014 (2)
- February 2014 (3)
- January 2014 (5)
- December 2013 (2)
- November 2013 (3)
- September 2013 (3)
- August 2013 (2)
- May 2013 (4)
- April 2013 (1)
- March 2013 (1)
- February 2013 (3)
- December 2012 (3)
- November 2012 (3)
- October 2012 (1)
- September 2012 (2)
- June 2012 (1)
- May 2012 (1)
- April 2012 (1)
- March 2012 (1)
- February 2012 (1)
- January 2012 (1)
- December 2011 (4)
- November 2011 (1)
- August 2011 (1)
- March 2011 (1)
- October 2010 (1)
- May 2010 (3)
- January 2010 (1)
- September 2009 (1)
- August 2009 (5)
- July 2009 (5)
- June 2009 (4)
- May 2009 (1)
- April 2009 (1)
- January 2009 (1)
- December 2008 (6)
- November 2008 (6)
- October 2008 (2)
- September 2008 (11)
- August 2008 (4)
- July 2008 (7)
- June 2008 (2)
- May 2008 (7)
- April 2008 (5)
- March 2008 (9)
- February 2008 (15)
- January 2008 (11)
- December 2007 (3)
modsecurity rule to filter CVE-2021-44228/LogJam/Log4Shell [update]
December 10, 2021
As a fast workaround, a friend of mine made a modsecurity rule to filter CVE-2021-44228/LogJam/Log4Shell, which he allowed me to share with you.
SecRule \
ARGS|REQUEST_HEADERS|REQUEST_URI|REQUEST_BODY|REQUEST_COOKIES|REQUEST_LINE|QUERY_STRING "jndi:ldap:" \
"phase:1, \
id:751001, \
t:none, \
deny, \
status:403, \
log, \
auditlog, \
msg:'Block: CVE-2021-44228 - deny pattern \"jndi:ldap:\"', \
severity:'5', \
rev:1, \
tag:'no_ar'"
New improved version:
SecRule \
ARGS|REQUEST_HEADERS|REQUEST_URI|REQUEST_BODY|REQUEST_COOKIES|REQUEST_LINE|QUERY_STRING "jndi:ldap:|jndi:dns:|jndi:rmi:|jndi:rni:|\${jndi:" \
"phase:1, \
id:751001, \
t:none, \
deny, \
status:403, \
log, \
auditlog, \
msg:'DVT: CVE-2021-44228 - phase 1 - deny known \"jndi:\" pattern', \
severity:'5', \
rev:1, \
tag:'no_ar'"
SecRule \
ARGS|REQUEST_HEADERS|REQUEST_URI|REQUEST_BODY|REQUEST_COOKIES|REQUEST_LINE|QUERY_STRING "jndi:ldap:|jndi:dns:|jndi:rmi:|jndi:rni:|\${jndi:" \
"phase:2, \
id:751002, \
t:none, \
deny, \
status:403, \
log, \
auditlog, \
msg:'DVT: CVE-2021-44228 - phase 2 - deny known \"jndi:\" pattern', \
severity:'5', \
rev:1, \
tag:'no_ar'
Jitsi Workaround for CVE-2021-44228/LogJam/Log4Shell
You surely heard of the LogJam / Log4Shell / CVE-2021-44228 – if not, take a look at this blog post. If you’re running Jitsi is most likely vulnerable and as there is no fix currently, you need a workaround which I provide here for you. You need to add -Dlog4j2.formatMsgNoLookups=True at the correct places in the file – the position is important.
/etc/jitsi/jicofo/config

/etc/jitsi/videobridge/config

And restart the processes or restart the server.
Howto install Wireguard in an unprivileged container (Proxmox)
April 14, 2019
Wireguard is the new star on the block concerning VPNs – and yes it has some benefits to the old VPN technologies but I won’t talk about them as there is much information about that on the Internet. This blog post just explains how to set it up in an unprivileged container. In my case everything is done on a Proxmox server. Let’s start:
On the Proxmox host itself we need to get the kernel module running. As Proxmox is based on Debian we just pin the Wireguard package from unstable, which is the recommended way by the Debian project in this case.
echo "deb http://deb.debian.org/debian/ unstable main" > /etc/apt/sources.list.d/unstable-wireguard.list
printf 'Package: *\nPin: release a=unstable\nPin-Priority: 90\n' > /etc/apt/preferences.d/limit-unstable
apt update
apt install wireguard pve-headers
If you get following:
Loading new wireguard-0.0.20190406 DKMS files...
Building for 4.15.18-9-pve
Module build for kernel 4.15.18-9-pve was skipped since the
kernel headers for this kernel does not seem to be installed.
Setting up linux-headers-4.9.0-8-amd64 (4.9.144-3.1) ...
you need to make sure the pve-headers for your current kernel is installed. If you installed it later, then you need to call:
dkms autoinstall
In both cases we test it with:
modprobe wireguard
If this works, we auto-load the module at boot, as the host does not know that a container needs that module later.
echo "wireguard" >> /etc/modules-load.d/modules.conf
Now we create our unprivileged container (in my case also Debian 9) and then install the user space tools:
echo "deb http://deb.debian.org/debian/ unstable main" > /etc/apt/sources.list.d/unstable-wireguard.list
printf 'Package: *\nPin: release a=unstable\nPin-Priority: 90\n' > /etc/apt/preferences.d/limit-unstable
apt update
and now something special – we want only the user space tools nothing more.
apt-get install --no-install-recommends wireguard-tools
A simple test that everything works can be done by creating temporary a wg0 device.
ip link add wg0 type wireguard
No output means everything worked. And we’re done, everything else is the same as running Wireguard without container – just choose your howto for this.
Howto install Bitwarden in a LXC container (e.g. Proxmox)
January 13, 2019
As many of you know me, I’m quite serious about security and therefore a believer in the theory that a service which is not reachable (e.g. from the Internet) cannot be attacked as easily as one that it. Looking at password managers this makes choosing not that easy. Sure there is Keepass and the descendants, but they have the problem that the security is based solely on the master password and the end device security. Knowing friends that use Google Drive for syncing the password file between their devices, I looked at that option, but it was not right for me (e.g. Browser integration, 2FA, …).
Password managers like Lastpass or 1Password are also not the right solution for me. Yes, I believe that their crypto is good, and they never see the passwords of their users, but the 2FA is only as good as the lost password/2FA reset feature is. I’ve read and seen to many attacks on that to rely on it.
All of this leads to Bitwarden, it provides the same level of functionality as Lastpass or 1Password but is OpenSource and can be hosted on my own server. Not opening it up to Internet and using it from remote only via VPN (which I have anyway) make for a real small attack surface. This blog post shows how I installed it within a Proxmox LXC container, which I did to isolated it from other stuff and therefore there are no dependencies, if I need to upgrade something. I don’t like to install anything on the Proxmox host itself. As this is my first try, and I run into a problem with an unprivileged container and docker within it, this setup works currently only with a privileged container. I know this is not that good, but in this case it is a risk I can accept. If you find a solution to get it running in an unprivileged container please send me an email or write a comment.
LXC container
After creating the LXC container (2Gb RAM, >5GB HD) with Debian 9, don’t start the container at once. You need to add following to /etc/modules-load.d/modules.conf
aufs
overlay
And if you don’t want to boot load the modules with
modprobe aufs
modprobe overlay
If you don’t do this your installation will get gigantic (over 30gb). Now we just need to add following to /etc/pve/lxc/<vid>.conf
#insert docker part below
lxc.apparmor.profile: unconfined
lxc.cgroup.devices.allow: a
lxc.cap.drop:
Now you can start the container and enter it, we’ll check later if all was correct, but we need docker for this.
Docker and Docker Composer
Some requirements for docker
apt install apt-transport-https ca-certificates curl gnupg2 software-properties-common
and now we can add the repository for docker
curl -fsSL https://download.docker.com/linux/debian/gpg | apt-key add -
add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/debian $(lsb_release -cs) stable"
and now we can install it with
apt-get update apt-get install docker-ce
The Docker Composer which is shipped with Debian is too old to work with this docker, so we need following:
curl -L "https://github.com/docker/compose/releases/download/1.23.1/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose
and add /usr/local/bin/ to the path variable by adding
PATH=/usr/local/bin:$PATH
to .bashrc and calling it directly in the bash to get it set without starting a new bash instance. I know that a package would be better, couldn’t find one, so this is a temporary solution. If someone finds a better one, leave it in the comments below.
Now we need to check if the overlay stuff is working by calling docker info and hopefully you get also overlay2 as storage driver:
Containers: 0
Running: 0
Paused: 0
Stopped: 0
Images: 0
Server Version: 18.06.1-ce
Storage Driver: overlay2
Backing Filesystem: extfs
Supports d_type: true
Native Overlay Diff: true
Logging Driver: json-file
Bitwarden
Now we just need following:
curl -s -o bitwarden.sh https://raw.githubusercontent.com/bitwarden/core/master/scripts/bitwarden.sh
chmod +x bitwarden.sh
./bitwarden.sh install
./bitwarden.sh start
./bitwarden.sh updatedb
And now you’re done, you’ve your own password manager server which also supports Google Authenticator (Time-based One-time Password Algorithm (TOTP) as second factor. Maybe I’ll write a blogpost how to setup a Yubikey as 2FA (desktop and mobile) later.
QuickTip: Howto secure your Mikrotik/RouterOS Router and specially Winbox
October 6, 2018
I didn’t post anything about the multiple security problems in the Mikrotik Winbox API, as I thought that whoever is leaving the management of a router open to the Internet should not configure routers at all. Of course it is common sense to open the management interface only on internal network interfaces and to source IP addresses you’re managing the routers. But as this is quick tip I’ll show you how I configure my Mikrotiks for years.
/ip service
set telnet address=0.0.0.0/0 disabled=yes
set ftp address=0.0.0.0/0 disabled=yes
set www address=0.0.0.0/0 disabled=yes
set ssh address=10.7.0.0/16
set api disabled=yes
set winbox address=127.0.0.1/32
set api-ssl disabled=yes
As you see I’ve only enabled ssh and winbox and winbox is only listening on localhost. The ssh is protected with the Firewall to to be only reachable from my admin network. Also I disable the weak ciphers:
/ip ssh set strong-crypto=yes
And I’ve configured public key authentication for the ssh access. Now your question is how to access the router with winbox? Simple, use ssh port forwarding. So the Winbox API is only accessible by users that have a valid ssh logon – and ssh is much more robust and secure than Winbox. On Linux the port forwarding is done like this:
ssh -L 8291:127.0.0.1:8291 admin@<mikrotik>
On Windows you can do that same with Putty. In Winbox just connect to localhost:
Some VPN providers leak your IPv6 IP address
August 10, 2018
Just a short note. Today a friend called me if I could help him to get TV streaming from TV stations in the US running. When I looked at it, he even selected a VPN provider which offers servers in the US to circumvent the Geo restrictions, but still it didn’t work. He showed me the NBC website where the first ad was shown and than the screen stayed black. Having no experience with VPN providers and TV streaming sites I first checked the openvpn configuration and made sure that the routing table was correct (sending all non local traffic to the VPN). Looked good, so I opened the developer tools in the browser and saw following repeating.
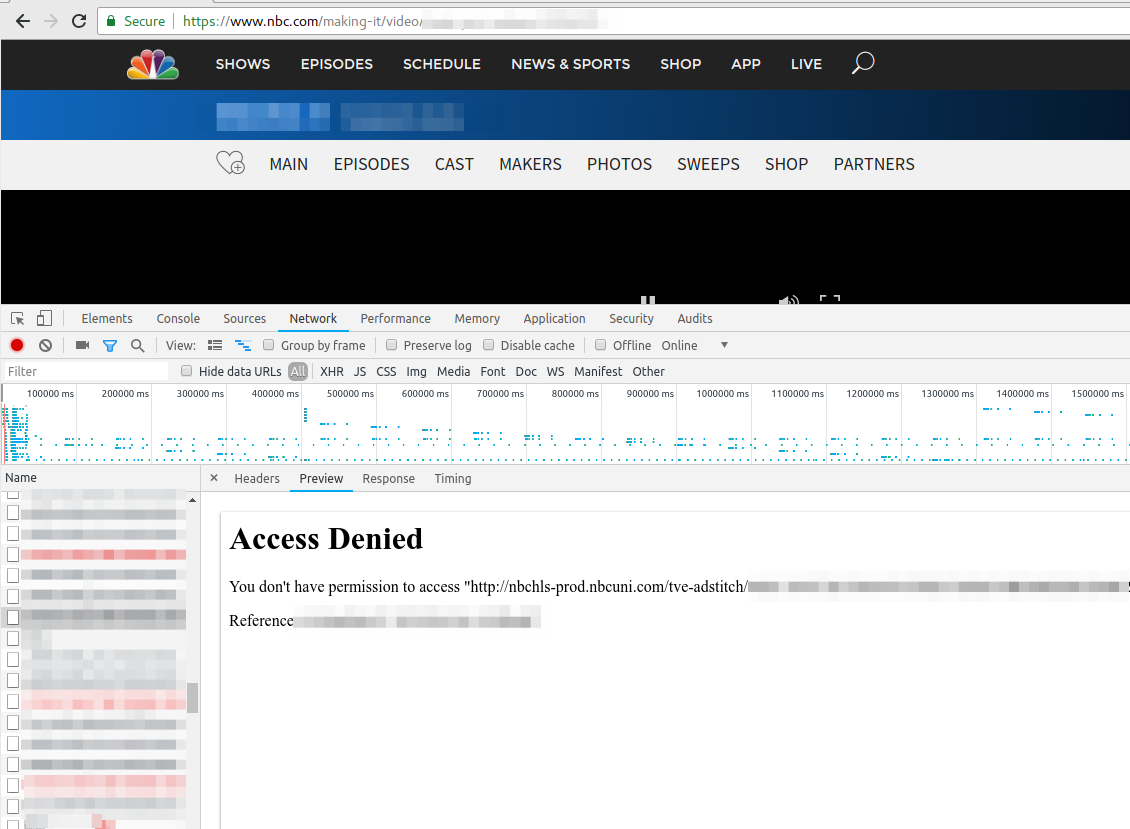
Searching the Internet did not provide an answer … than I just tried to download the file with wget and I got following:
$ wget http://nbchls-prod.nbcuni.com/tve-adstitch/4421/xxxx-1.ts
--2018-08-10 19:20:20-- http://nbchls-prod.nbcuni.com/tve-adstitch/4421/xxxx-1.ts
Resolving nbchls-prod.nbcuni.com (nbchls-prod.nbcuni.com)... 2600:1406:c800:495::308, 2600:1406:c800:486::308, 104.96.129.98
Connecting to nbchls-prod.nbcuni.com (nbchls-prod.nbcuni.com)|2600:1406:c800:495::308|:80... connected.
HTTP request sent, awaiting response... 403 Forbidden
2018-08-10 xx:xx:xx ERROR 403: Forbidden.
Seeing this it hit me … its using IPv6 … so I did a fast check with
% wget -4 http://nbchls-prod.nbcuni.com/tve-adstitch/4421/xxxx-1.ts
--2018-08-10 19:20:30-- http://nbchls-prod.nbcuni.com/tve-adstitch/4421/xxxx-1.ts
Resolving nbchls-prod.nbcuni.com (nbchls-prod.nbcuni.com)... 104.96.129.98
Connecting to nbchls-prod.nbcuni.com (nbchls-prod.nbcuni.com)|104.96.129.98|:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 242520 (237K)
So with a IPv4 request it worked. His VPN provider was leaking the IPv6 traffic to the Internet – that is potentially a security/privacy problem as many use a VPN provider to hide them! So make sure to check before relying on the VPN security/privacy.
A security minded guy forced to buy a Wifi enabled cleaning robot
August 1, 2017
First I want to tell you all that I wanted a vacuum cleaning robot without Internet connection, but I couldn’t find one which fulfilled the requirements. At first I thought the DEEBOT M81 from ECOVACS would be such a device (vacuum and mop combo and possible to carry between rooms as it works randomly), but don’t buy it if you’ve stairs. On the first day alone at home it went 2 floors down, somehow it did look okay and still worked after the kamikaze. We just needed to search for it through the whole house. After that I did some tests, I found out that it stops 6 times at the stairs and falls down the 7 or 8 time. Searching through the Internet showed me that I’m not the only one. The second problem was that configuring the timer differently for some days (like not cleaning on weekends) was not possible. After loosing my last chance for a non Internet connected device I went for the DEEBOT M81 Pro which needs an Android or IPhone app and WiFi, if you want to configure the timer for not cleaning on weekends. This is my story about that – I guess – a typical IoT device.

The App – ECOVACS
After unpacking and charging of the robot, I went and installed the App on my test mobile. Why not on my real mobile? Take a look at the required permissions:




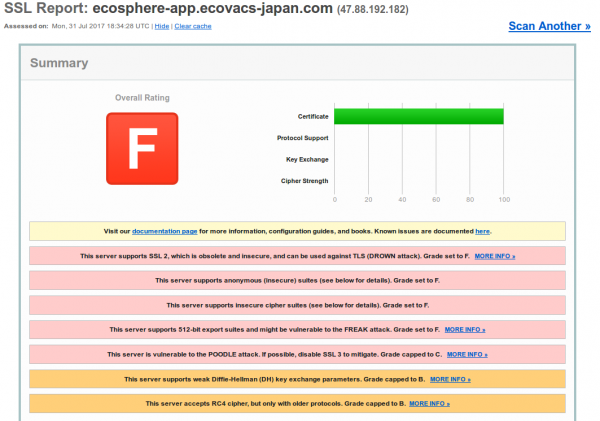
I though that is just an App to control my vacuum robot …. guess not. Anyway I installed it on my test system and created a dummy user. Of course I took a look at the traffic. First it connects to ecosphere-app.ecovacs-japan.com,
![]()
where it does an HTTPS connect. Hm, maybe thats better than I thought, but the TLS config of the server is bad, but at least it encrypted – so there is still hope.
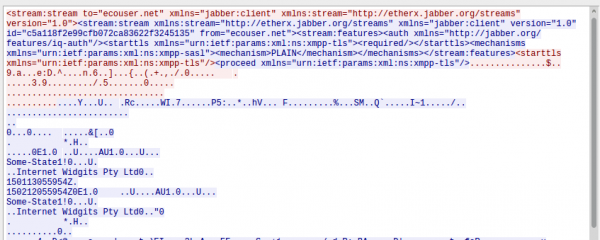
Looking at the other traffic I saw a XMPP / jabber connection (lbat.ecouser.net / 47.91.78.247), which was encrypted, but sadly with a self signed certificate. I’ll thought I’ll take a look at the traffic via MitM later, lets get it to work before.
Getting it to work
It looks like the robot is creating a SSID for the App on the mobile to connect to, after you pressed the WiFi button >3 sec. So the exchange of the WiFi password seems to secure enough. But it took me almost 1h to get the robot to connect to my IoT network and I didn’t find any information or tips online. I changed following on my side to get it to work, maybe that helps somebody else:
- I enabled the location stuff (which I’ve disabled by default) on the mobile as I remembered the WiFi Analyser App always tells me to enabled that to sees WiFi networks.
- I needed to change my IoT network to support legacy WiFi modes. My normal setup is:

I needed to change it to following in order for the robot to be able to connect:
Robot traffic
The first request from the robot after getting an IP address is to request a HTTP connection to lbo.ecouser.net (47.91.78.247) on Port 8007
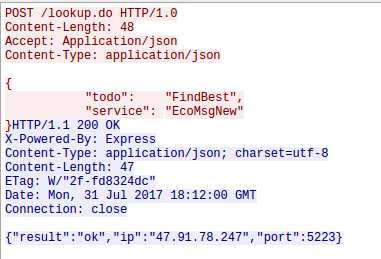
Hey we know the IP address and port – that’s the Jabber server the App also connects to. But before the robot connects to the Jabber server he does a second HTTP request, this time to an IP address (47.88.193.19:8005) and not a DNS name. Thats interesting:
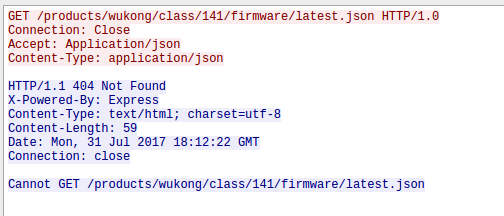
That looks like a check for newer firmware …. firmware updates unencrypted .. what can possible go wrong here. As the request currently returns no new firmware I can’t look at that more closely – something for the future. Checking Shodan Info on that IP address is interesting. It runs a portmapper and ntp server reachable from the internet … someone already using that as DDOS amplifier? I’m not talking about the not configured nginx which also leaks IP addresses in the certificate: IP Address:120.26.244.107, IP Address:121.41.41.198, IP Address:47.88.193.19
Let’s go back to the Jabber server the robot connect to. The App uses a self signed certificate “protected” channel but the robot does connect completely in the clear – thats nice so I don’t need to do a MitM attack. The wireshark trace is so full on information that I’m really not sure what I can show you without making it too easy for you to control my robot.

Following is shown in the screenshot (which shows only a a part of the communication):
- The logon to the server via PLAIN authentication, which is comprised of
- username: Is the serial number of the device, which is also printed onto the box the device is sold in.

- password: Looks like a MD5 hash of something, as its 32 hex chars – something to investigate
- username: Is the serial number of the device, which is also printed onto the box the device is sold in.
- It shares its online (presence status in jabber terms) with the app
- It gets asked for a version, I guess the firmware version which it returns as 0.16.46 – hope a thats already stable
Looking at later traffic following requests issued by the app:
- GetDeviceInfo
- SetTime
- GetChargeState
- GetBatteryInfo
- GetWKVer
- GetError
- GetOnOff
- GetSched
- GetLifeSpan
I didn’t control the device via the App otherwise there should be much more commands.
Questions and thoughts
I don’t really see a peering which makes sure that only the right App can control a robot, so it is maybe possible to control other robots. As the user ID used on the Jabber server is just the serial number with @141.ecorobot.net/atom added, it should be ease to guess additional user IDs. There is no need to know the password of the robot. On the other side it should be possible to create your own Jabber server and redirect traffic to it. Also writing a DIY App without all that App permissions should be possible and not to hard. The robot I bought is not so interesting for an attacker as it cannot provide room layouts as the more expensive ones provide. The screenshots of the App show what is possible:

I guess I wait for the next versions of the robots that provide a microphone and/or a camera – than it gets really interesting.
As I was able to configure the schedules via the App and set the time, I’ll try if that still works if the robot is not able to connect to the Internet. If so I’ll got that route and enable the Internet connection only if I need to change the schedules.
Ps: you should really have a separate IoT network.
WannaCry happened and nobody called me during my vacation – I tell you why
May 18, 2017
I was since last Wednesday on a biking trip through Austria and Bavaria, when on Friday reading main stream media the world broke down with WannaCry. Ok, I thought sensationalism by the main media but now as I’m at home, I cannot believe what I read in tech blogs and the IT media. I won’t link all of them here, just the one I plainly can’t understand and to which I disagree in the strongest way possible – telling plainly patching is hard and we can’t do anything.
Lets start with how a WannaCry infection spreads through a company.
- The malware needed to get into the company network – be it via open SMB ports (445 TCP) to the Internet and via Email. As I read through the articles its not 100% clear how the infection – lets assume both methods have been used for this post
- In the second case a user clicks onto the attachment and the malware gets executed
- Than it searches through the company network and tries with a RCE (remote code execution) to infect other PCs
- It encrypted the local hard drive
Now lets talk why this should not have been any problem in your organization
- Port 445 TCP reachable from the Internet? Really? If you’re unsure, quickly go to Shodan and type into the search field
net:"xxx.xxx.xxx.xxx/yy"withxxx.xxx.xxx.xxxyou IP address range followed by theyysubnet mask and take a look if you know about open ports and services. - And now lets take a look at all the stuff I wrote over a year ago, what you should have done before the Locky malware happened (yes this is not the first ransomware making big waves), to be not affected:Stop panicking about the Locky ransomware [Update 2]
- For the Email infection vector:
- Block EXE attachments in emails
- Remove active code from Word, Excel and Powerpoint files by default
- Block EXE downloads on the Proxy
- For both infection vectors:
- Use application white-listing – we moved to whitelisting for firewall rules a long time ago, its past time to do that for applications. Guess why there is not so much iPhone malware – Apple is effectively white-listing software.
- Block client 2 client traffic – Even if that is not possible on a day2day basis, it should be prepared to be enabled in a case of emergency.
With one of the last two alone an widespread infection would not have been possible.
- For the Email infection vector:
- Microsoft provided a patch on March 14 and called the vulnerability critical. Lets take a look when Microsoft calls some vulnerabilities critical and when important. The difference is that with important the user gets asked and than infected, with critical there is nothing, just infection. So important is remote code execute and critical is wormable remote code execution.

And at last take a look at following text from Microsoft: “Mitigating Factors: Microsoft has not identified any mitigating factors for this vulnerability.” To make it short if you read about such a vulnerability in Windows and know that an exploit is in the wild, drop everything and start patching that hole at once.

Looking at the above ways the malware/worm could have easily been blocked. Anyway at last I really want now to take a look at the post linked above from the SMBlog by Steven M. Bellovin.
- Because patching is very hard and very risk, and the more complex your systems are, the harder and riskier it is.
Thats not true in this case.- Port 445 open to the Internet, no real network separation, deactivated local Windows Firewall and still have SMB1 activated on Windows Client Systems (see Microsoft recommendation from 2016) – thats not at patching problem, thats a security policy failure (e.g. base hardening of operating systems)
- standard client PCs (for the normal employee) not patched – not talking about special systems – we patch thousand PCs every month after the Windows patches are released without any problems in years. The special systems needed to get infected after all by something.
- If non company managed client PCs got connected to the network and infected special systems, its a failure in network access control – plane and simple
- no mitigation prepared for a case like a worm breakout – Just to make a point, we prepared a client2client block ACLs for all edge switches, which could be activated within a few minutes, in 2011 – as you newer can know. This is a missing emergency plan like required in ISO 27001.
- 2 month window for patching an remote code execution wormable vulnerability. If it was not possible in 2 month to patch something like that, than the company has a high technical/security debt. This is a management failure.
- still running non supported software – that is a management failure, by not making correct contracts with the vendor or ignoring the problem like a Ostrich.
- So—if you’re the CIO, what do you do? Break the company, or risk an attack? (Again, this is an imaginary conversation.)
Thats the wrong question – if the CIO is at the questing he has done a bad job before:- All your critical software should have a maintenance contract which specially handles security updates (and specially the timeline) of the underlaying operating system and the software itself and there must be contractual penalty in it. Done that for year now with “call for bids” – Big IT companies provide that security handling without you asking for it – so this is mainly for special software.
- If the IT department has not the time to patch everything a Triage needs to be done. The vulnerabilities with the highest probability and potential for damage need to be patched first – this vulnerability must have been on the top of any list.
- The systems are not as in German is called “Stand der Technik” which can be translated as “state of the art” – an Windows XP system is not state of the art, no meaningful network separation is not state of the art, …..
- That patching is so hard is very unfortunate. Solving it is a research question. Vendors are doing what they can to improve the reliability of patches, but it’s a really, really difficult problem.
- Ok patching might be not a easy as it could be but
- A big institution that got caught by this malware did leave the back door open and is now complaining that a herd of wild boars went through the house and did damage.
- the security and IT department just failed at their job – just do a postmortem without finger pointing and fix the problems. I’m quite sure the affected IT departments got caught also by the Locky malware and didn’t learn a thing.
- Vendors doing not enough, sure in this case Microsoft did patch it but specially with IoT devices vendor to nothing.
- Searching through Google for problems after installing MS17-010 reviles only a few post after billions of updated PCs –> there are no problems with this patch –> no reason to not install it
- Ok patching might be not a easy as it could be but
So thats my view onto the WannaCry stuff after being on vacation ….. tell me your views – did I miss something?
Mitigating application layer (HTTP(S)) DDOS attacks
April 23, 2017
DDOS attacks seem to be new norm on the Internet. Years before only big websites and web applications got attacked but nowadays also rather small and medium companies or institutions get attacked. This makes it necessary for administrators of smaller sites to plan for the time they get attacked. This blog post shows you what you can do yourself and for what stuff you need external help. As you’ll see later you most likely can only mitigate DDOS attacks against the application layer by yourself and need help for all other attacks. One important part of a successful defense against a DDOS attack, which I won’t explain here in detail, is a good media strategy. e.g. If you can convince the media that the attack is no big deal, they may not report sensational about it and make the attack appear bigger and more problematic than it was. A classic example is a DDOS against a website that shows only information and has no impact on the day to day operation. But there are better blogs for this non technical topic, so lets get into the technical part.
different DDOS attacks
From the point of an administrator of a small website or web application there are basically 3 types of attacks:
- An Attack that saturates your Internet or your providers Internet connection. (bandwidth and traffic attack)
- Attacks against your website or web application itself. (application attack)
saturation attacks
Lets take a closer look at the first type of attack. There are many different variations of this connection saturation attacks and it does not matter for the SME administrator. You can’t do anything against it by yourself. Why? You can’t do anything on your server as the good traffic can’t reach your server as your Internet connection or a connection/router of your Internet Service Provider (ISP) is already saturated with attack traffic. The mitigation needs to take place on a system which is before the part that is saturated. There are different methods to mitigate such attacks.
Depending on the type of website it is possible to use a Content Delivery Networks (CDN). A CDN basically caches the data of your website in multiple geographical distributed locations. This way each location gets only attacked by a part of the attacking systems. This is a nice way to also guard against many application layer attacks but does not work (or not easily) if the content of your site is not the same for every client / user. e.g. an information website with some downloads and videos is easily changed to use a CDN but a application like a Webmail system or an accounting system will be hard to adapt and will not gain 100% protection even than. An other problem with CDNs is that you must protect each website separately, thats ok if you’ve only one big website that is the core of your business, but will be a problem if attacker can choose from multiple sites/applications. An classic example is that a company does protect its homepage with an CDN but the attacker finds via Google the Webmail of the companies Exchange Server. Instead of attacking the CDN, he attacks the Internet connection in front of the Qebmail. The problem will now most likely be that the VPN site-2-site connections to the remote offices of the company are down and working with the central systems is not possible anymore for the employees in the remote locations.
So let assume for the rest of the document that using a CDN is not possible or not feasible. In that case you need to talk to your ISPs. Following are possible mitigations a provider can deploy for you:
- Using a dedicated DDOS mitigation tool. These tools take all traffic and will filter most of the bad traffic out. For this to work the mitigation tool needs to know your normal traffic patterns and the DDOS needs to be small enough that the Internet connections of the provider are able to handle it. Some companies sell on on-premise mitigation tools, don’t buy it, its wasting money.
- If the DDOS attack is against an IP address, which is not mission critical (e.g. attack is against the website, but the web application is the critical system) let the provider block all traffic to that IP address. If the provider as an agreement with its upstream provider it is even possible to filter that traffic before it reaches the provider and so this works also if the ISPs Internet connection can not handle the attack.
- If you have your own IP space it is possible for your provider(s) to stop announcing your IP addresses/subnet to every router in the world and e.g. only announce it to local providers. This helps to minimize the traffic to an amount which can be handled by a mitigation tool or by your Internet connection. This is specially a good mitigation method, if you’re main audience is local. e.g. 90% of your customers/clients are from the same region or country as you’re – you don’t care during an attack about IP address from x (x= foreign far away country).
- A special technique of the last topic is to connect to a local Internet exchange which maybe also helps to reduce your Internet costs but in any case raises your resilience against DDOS attacks.
This covers the basics which allows you to understand and talk with your providers eye to eye. There is also a subsection of saturation attacks which does not saturate the connection but the server or firewall (e.g. syn floods) but as most small and medium companies will have only up to a one Gbit Internet connection it is unlikely that a descend server (and its operating system) or firewall is the limiting factor, most likely its the application on top of it.
application layer attacks
Which is a perfect transition to this chapter about application layer DDOS. Lets start with an example to describe this kind of attacks. Some years ago a common attack was to use the ping back feature of WordPress installations to flood a given URL with requests. I’ve seen such an attack which requests on a special URL on an target system, which did something CPU and memory intensive, which let to a successful DDOS against the application with less than 10Mbit traffic. All requests were valid requests and as the URL was an HTTPS one (which is more likely than not today) a mitigation in the network was not possible. The solution was quite easy in this case as the HTTP User Agent was WordPress which was easy to filter on the web server and had no side effects.
But this was a specific mitigation which would be easy to bypassed if the attacker sees it and changes his requests on his botnet. Which also leads to the main problem with this kind of attacks. You need to be able to block the bad traffic and let the good traffic through. Persistent attackers commonly change the attack mode – an attack is done in method 1 until you’re able to filter it out, than the attacker changes to the next method. This can go on for days. Do make it harder for an attacker it is a good idea to implement some kind of human vs bot detection method.
I’m human
The “I’m human” button from Google is quite well known and the technique behind it is that it rates the connection (source IP address, cookies (from login sessions to Google, …) and with that information it decides if the request is from a human or not. If the system is sure the request is from a human you won’t see anything. In case its sightly unsure a simple green check-mark will be shown, if its more unsure or thinks the request is by a bot it will show a CAPTCHA. So the question is can we implement something similar by ourself. Sure we can, lets dive into it.
peace time
Set an special DDOS cookie if an user is authenticated correctly, during peace time. I’ll describe the data in the cookie later in detail.
war time
So lets say, we detected an attack manually or automatically by checking the number of requests eg. against the login page. In that case the bot/human detection gets activated. Now the web server checks for each request the presence of the DDOS cookie and if the cookie can be decoded correctly. All requests which don’t contain a valid DDOS cookie get redirected temporary to a separate host e.g. https://iamhuman.example.org. The referrer is the original requested URL. This host runs on a different server (so if it gets overloaded it does not effect the normal users). This host shows a CAPTCHA and if the user solves it correctly the DDOS cookie will be set for example.org and a redirect to the original URL will be send.
Info: If you’ve requests from some trusted IP ranges e.g. internal IP address or IP ranges from partner organizations you can exclude them from the redirect to the CAPTCHA page.
sophistication ideas and cookie
An attacker could obtain a cookie and use it for his bots. To guard against it write the IP address of the client encrypted into the cookie. Also put the timestamp of the creation of the cookie encrypted into it. Also storing the username, if the cookie got created by the login process, is a good idea to check which user got compromised.
Encrypt the cookie with an authenticated encryption algorithm (e.g. AES128 GCM) and put following into it:
- NONCE
- typ
- L for Login cookie
- C for Captcha cookie
- username
- Only if login cookie
- client IP address
- timestamp
The key for the encryption/decryption of the cookie is static and does not leave the servers. The cookie should be set for the whole domain to be able to protected multiple websites/applications. Also make it HttpOnly to make stealing it harder.
implementation
On the normal web server which checks the cookie following implementations are possible:
- The apache web server provides a module called mod_session_* which provides some functionality but not all
- The apache module rewriteMap (https://httpd.apache.org/docs/2.4/rewrite/rewritemap.html) and using „prg: External Rewriting Program“ should allow everything. Performance may be an issue.
- Your own Apache module
If you know about any other method, please write a comment!
The CAPTCHA issuing host is quite simple.
- Use any minimalistic website with PHP/Java/Python to create cookie
- Create your own CAPTCHA or integrate a solution like Recaptcha
pro and cons
- Pro
- Users than accessed authenticated within the last weeks won’t see the DDOS mitigation. Most likely these are your power users / biggest clients.
- Its possible to step up the protection gradually. e.g. the IP address binding is only needed when the attacker is using valid cookies.
- The primary web server does not need any database or external system to check for the cookie.
- The most likely case of an attack is that the cookie is not set at all which does take really few CPU resources to check.
- Sending an 302 to the bot does create only a few bytes of traffic and if the bot requests the redirected URL it on an other server and there no load on the server we want to protect.
- No change to the applications is necessary
- The operations team does not to be experts in mitigating attacks against the application layer. Simple activation is enough.
- Traffic stats local and is not send to external provider (which may be a problem for a bank or with data protections laws in Europe)
- Cons
- How to handle automatic requests (API)? Make exceptions for these or block them in case of an attack?
- Problem with non browser Clients like ActiveSync clients.
- Multiple domains need multiple cookies
All in all I see it as a good mitigation method for application layer attacks and I hope the blog post did help you and your business. Please leave feedback in the comments. Thx!
Implementing IoT securely in your company – Part 3
February 2, 2017
This is Part 3 of the series implementing IoT securely in your company, click here for part 1 and here for part 2. As it is quite common that new IoT devices are ordered and also maintained by the appropriate department and not by the IT department, it is important that there is a policy in place.
This policy is specially important in this case as most non IT departments don’t think about IT security and maintaining the system. They are often used to think about buying a device and it will run for years and often even longer, without doing much. We on the other hand in the IT know that the buying part is the easy part, maintaining it is the hard one.
Extend existing security policies
Most companies won’t need to start from scratch, as they most likely have policies for common stuff like passwords, patching and monitoring. The problem here is the scope of the policies and that you’re current able to technically enforce many of them:
- Most passwords are typically maintained by an identity management system and the password policy is therefore enforced for the whole company. The service/admin passwords are typically configured and used by members of the IT department. For IoT devices that maybe not true as the devices are managed by the using department and technically enforcing it may not be possible.
- Patching of the software is typically centrally done by the IT department, be it the client or server team. But who is responsible for updating the IoT devices? Who monitors that updates are really done? How does he monitor that? What happens if a department does not update their devices? What happens if a vendor stops providing security updates for a given device?
- Centrally by the IT department provided services are generally monitored by the IT department. Is the IT department responsible for monitoring the IoT devices? Who is responsible for looking into the problem?
You should look at this and write it down as a policy which is accepted by the other departments before deploying IoT devices. In the beginning they will say yes sure we’ll update the devices regularly and replace the devices before the vendors stops providing security updates – and often can’t remember it some years later.
Typical IoT device problems
Beside extending the policies to cover IoT devices it’s also important to check the policies if the fit the IoT space and cover typical problems. I’ll list some of them here, which I’ve seen done wrong in the past. Sure some of them also apply for normal IT server/services but are maybe consider so basically that everyone just does it right, that it is maybe not covered by your policy.
- No Update is possible
Yes, there are devices out in the wild that can’t be updated. What does your policy say? - Default Logins
Many IoT devices come with a default login and as the management of the devices is done via a central (cloud) management system, it is often forgotten that the devices may have also a administration interface.What does your policy say? - Recover from IoT device loss
Let’s assume that an attacker is able to get into one IoT device or that the IoT device gets stole. Is the same password used on the server? Do all devices use the same password? Will the IT department get informed at all? What does your policy say? - Naming and organizing things
For IT devices it’s clear that we use the DNS structure – works for servers, switches, pc’s. Make sure that the same gets used for IoT device. What does your policy say? - Replacing IoT devices
Think about > 100 IoT devices running for 4 years and now some break down, and the the devices are end of sales. Can you connect new models to the old ones? does someone keep spare parts? What does your policy say? - Self signed certificates
If the system/devices uses TLS (e.g. HTTPS) it needs to be able to use your internal PKI certificates. Self signed certificates are basically the same as unencrypted traffic. What does your policy say? - Disable unused services
IoT enable often all services by default, like I had a device providing a FTP and telnet server – but for administration only HTTP was ever used. What does your policy say?
I hope that article series helps you to implement IoT devices somewhat securely.
Powered by WordPress
Entries and comments feeds.
Valid XHTML and CSS.
40 queries. 0.077 seconds.